Page Not Found
Abstract:
Page not found. Your pixels are in another canvas.
Citation:

A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Abstract:
Page not found. Your pixels are in another canvas.
Citation:
Abstract:
About me
Citation:
Citation:
Citation:
Citation:
Citation:
Citation:
Abstract:
This is a page not in th emain menu
Citation:
Citation:
Citation:
Citation:
Citation:
Citation:
Citation:
Citation:
Citation:
Citation:
Citation:
Citation:
Citation:
Published:
Abstract:
This post will show up by default. To disable scheduling of future posts, edit config.yml and set future: false.
Citation:
Published:
Abstract:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Citation:
Published:
Abstract:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Citation:
Published:
Abstract:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Citation:
Published:
Abstract:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Citation:
Abstract:
Short description of portfolio item number 1
Citation:
Abstract:
Short description of portfolio item number 2
Citation:
Published:
Abstract:
retrieves upto 250,000 Search engine results per day. With a $5/month VPN subscription, can extract upto 10,000+ search results per query per hour (120x cheaper than Google Search API). Built using Python and Selenium, coordinates multiple PhantomJS browser instances, each connected to a SOCKS5 proxy.
Citation:
Published:
Abstract:
We design an automated agent to play 2-on-2 games in SuperTuxKart IceHockey. Our two-stage system composes of a "vision" stage which takes as input the image of the player's Field of View and predicts world-state attributes. For vision, we train a multi-task CenterNet model (with U-Net backend), to predict whether hockey puck was on-screen (classification), puck's x-y coordinates (aimpoint regression) and distance from player (regression). These are consumed by a "controller" stage which return actions that update the world-state by "dribbling" puck towards goal, or defending against the opposing AI team.
Citation:
Published:
Abstract:
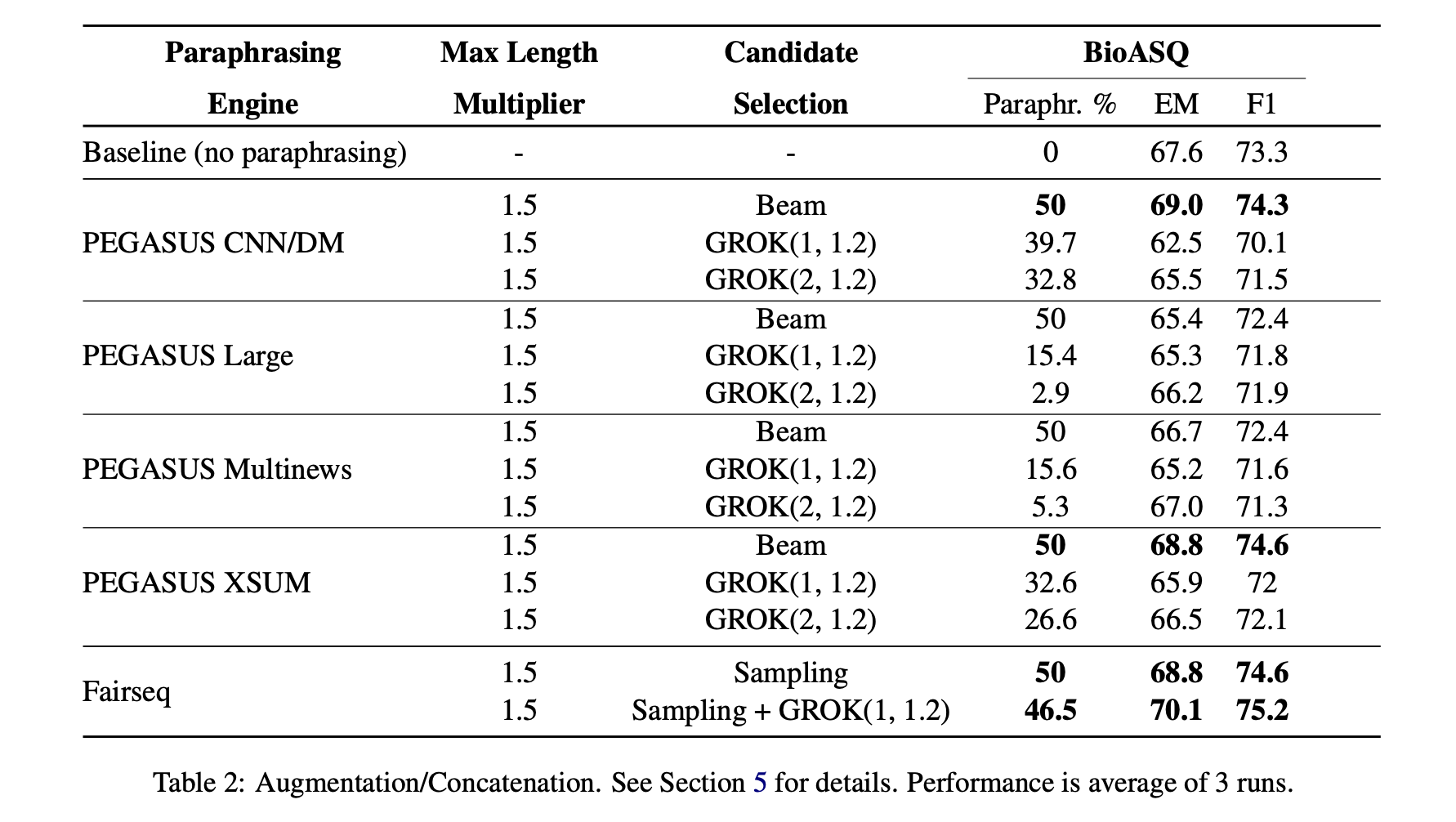
A common issue when asking questions is that they might be prone to misinterpretation: most of us have experienced when a colleague or teacher misinterprets a question and provides an answer which is tangential to the information we desire, or incomplete. This problem is exacerbated over text, where visual and emotion cues are not transmittable. We hypothesize that question answering models face the same issues as the human responder in such situations: when asked an ambiguous question, they might be unsure what to retrieve from the given passage. We propose paraphrasing the question with pre-trained language models, to improve answer retrieval and robustness to ambiguous questions. We introduce a new scoring metric, GROK, to evaluate and select good paraphrases. We show that this metric improved upon paraphrase selection via beam search for downstream tasks, and that this metric combined with data augmentation via backtranslation increases question answering performance on the NewsQA and BioASQ datasets, improving EM by 2.5% and F1 by 1.9% over-and-above the baseline on the latter.
Citation:
Published:
Abstract:
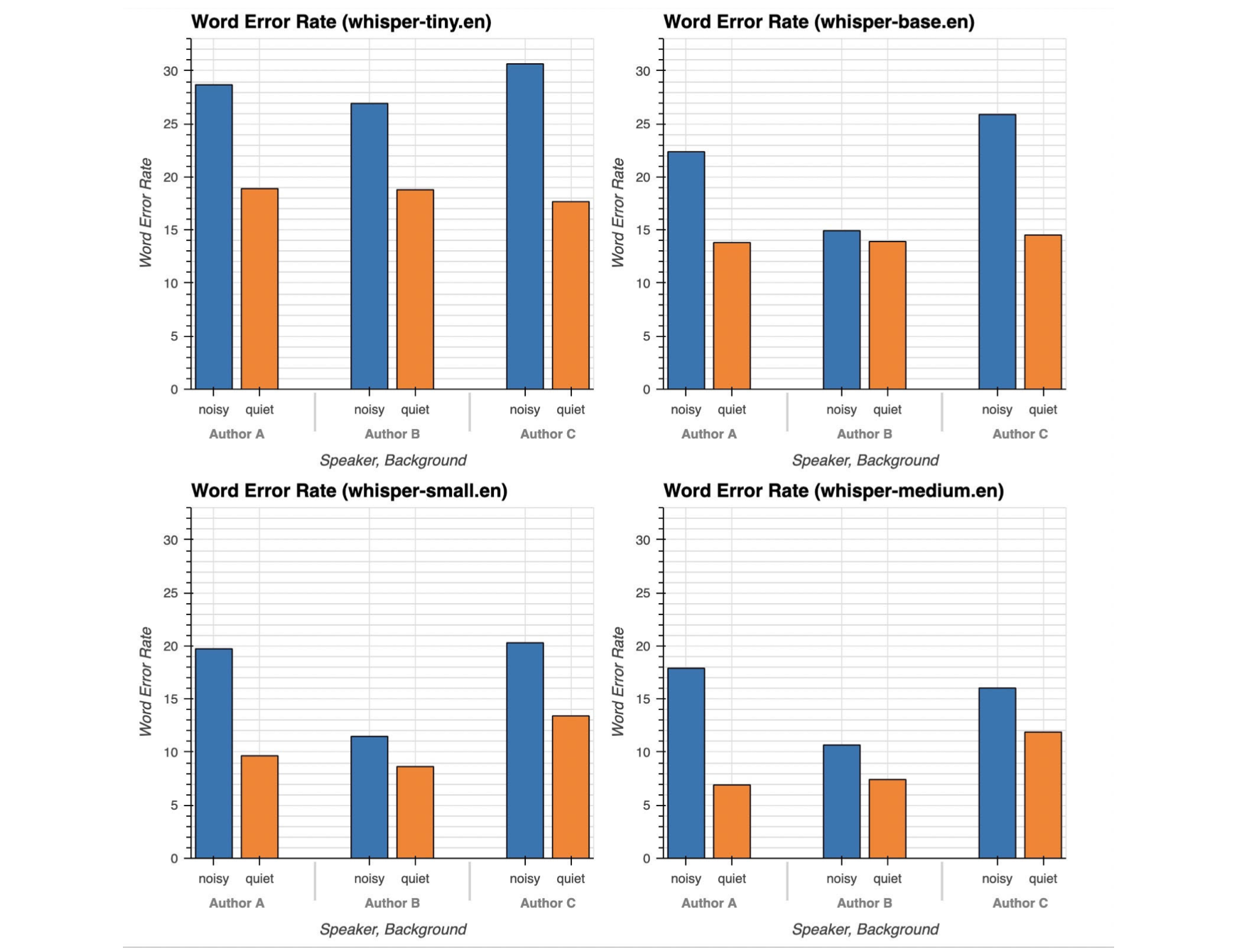
We study the performance of OpenAI's Whisper model, the state-of-the-art Speech-to-text model, in noisy urban environments. To do so, we create a dataset consisting of 134 minutes of us reading out loud in both quiet and noisy urban environments (subway, street and cafe) and manually annotating the recordings at 30 second intervals. Using a powerful multi-GPU AWS cluster and distributed computing framework Ray, we find that Whisper performs significantly worse on speeches recorded in noisy environments than on those recorded in quiet environments, in contrast to assertions made by Whisper authors. This performance gap is particularly severe for small Whisper models. This finding is concerning since the small models, due to its low inference-time, are most likely to be deployed on handheld devices (like smartphones), and thus more likely to be exposed to outside noise that can degrade speech-to-text performance. To improve performance, we fine-tune the HuggingFace Whisper implementation on a split of our collected data. We find that fine-tuning on single-speaker noisy speech improves average Word Error Rate (WER) by 2.81 (from 28.76 to 25.95) and fine-tuning on multi-speaker noisy speech improves average WER by 2.61 (from 28.76 to 26.15). Thus we are able to successfully adapt OpenAI Whisper to function reliably in noisy urban environments.
Citation:
Published: IEEE International Conference on Computing, Communication and Security, 2018
Abstract:
Machine Learning has been steadily gaining traction for its use in Anomaly-based Network Intrusion Detection Systems (A-NIDS). Research into this domain is frequently performed using the KDD~CUP~99 dataset as a benchmark. Several studies question its usability while constructing a contemporary NIDS, due to the skewed response distribution, non-stationarity, and failure to incorporate modern attacks. In this paper, we compare the performance for KDD-99 alternatives when trained using classification models commonly found in literature: Neural Network, Support Vector Machine, Decision Tree, Random Forest, Naive Bayes and K-Means. Applying the SMOTE oversampling technique and random undersampling, we create a balanced version of NSL-KDD and prove that skewed target classes in KDD-99 and NSL-KDD hamper the efficacy of classifiers on minority classes (U2R and R2L), leading to possible security risks. We explore UNSW-NB15, a modern substitute to KDD-99 with greater uniformity of pattern distribution. We benchmark this dataset before and after SMOTE oversampling to observe the effect on minority performance. Our results indicate that classifiers trained on UNSW-NB15 match or better the Weighted F1-Score of those trained on NSL-KDD and KDD-99 in the binary case, thus advocating UNSW-NB15 as a modern substitute to these datasets.
Citation: Abhishek Divekar, Meet Parekh, Vaibhav Savla, Rudra Mishra, and Mahesh Shirole. "Benchmarking datasets for Anomaly-based Network Intrusion Detection: KDD CUP 99 alternatives". IEEE International Conference on Computing, Communication and Security (ICCCS 2018) (https://arxiv.org/abs/1811.05372)
Published: Workshop on Automated Machine Learning, Amazon Machine Learning Conference, 2020
Abstract:
Business teams at Amazon often need to classify products into different taxonomies such as GL, item type keyword (ITK), category/sub-category, browse node, tax code, export-compliance-code and hazmat. Due to the lack of ML expertise, these teams end up relying on human auditors or manually codify rules, which is not scalable or do not work in cases having data with high diversity. Existing ML solutions for AutoML product classification are either stand-alone applications that push the burden of model productionization onto users (e.g. SageMaker Autopilot and AutoGluon), or are production-friendly, but lack state-of-the-art AutoML capabilities and do not leverage the agility offered by modern tech ecosystems. In this paper, we present Entity Prediction Service (EPS), a configurable product classification solution designed to serve the end-to-end needs of Amazon teams. Leveraging the robust ecosystem of AWS services and Docker, EPS automatically fetches and pre-processes data from internal data sources, trains and tunes models, performs inference, and enables one-click deployment into production. Each step offers a granular level of configurability, with default parameters backed by a robust set of scientific benchmarks. This helps serve customers across the spectrum of Machine Learning expertise, enabling Business Associates, SDEs and Applied Scientists to build high quality product classification models and deploy them on Amazon systems for continuous classification.
Citation: Gaurav Manchanda*, Abhishek Divekar*, Akshay Jagatap, Prit Raj, Vinayak Puranik, Nikhil Rasiwasia, Ramakrishna Nalam, and Jagannathan Srinivasa. "Entity Prediction Service: a configurable, end-to-end AutoML system". Workshop on Automated Machine Learning at the 8th conference of Amazon Machine Learning (AMLC 2020) (Internal venue)
Published: 2nd ASCS Applied Science Workshop, 2021
Abstract:
The data available in Amazon's catalog is rich and diverse; however, it is also highly irregular and often challenging to employ directly for business or Machine Learning applications. Frequent issues include low fill-rate of catalog attributes, noise in attributes, dataset shift between train and real-world distributions, and potential abuse in externally-sourced fields such as Generic Keywords and Browse Node. In this paper, we work backward from the goal of building high-precision classifiers to predict “Leaf Nodes” of Amazon's Browse taxonomy, to address the issue of purposeful or accidental mis-noding in the face of aforementioned challenges. Our findings indicate that weakly-supervised datasets collected using intuitive filters - based on Glance Views (GVs) and Total Orders - are effective in eliminating potential noise in the training data (2-4% improvement in accuracy). Further, evaluating a curated set of algorithms illustrates problems inherent in weak supervision that affect both linear models and pre-trained Transformer architectures. To address these problems, we explore multi-modal ensembling and show how ensembles combining multiple information sources outperform models trained on a single modality (additional 2-5% improvement in accuracy). Finally, we describe our success deploying these models on the IN marketplace to automatically correct Leaf Nodes for high-GV and 0-GV products, which has led to >3.5X improvement in audit efficiency and 5.5MM Leaf Node corrections overall.
Citation: Abhishek Divekar, Vinayak Puranik, Zhenyu Shi, Jinmiao Fu, and Nikhil Rasiwasia. "LEAP: LEAf node Predictions in the wild". 2nd ASCS Applied Science Workshop, 2021 (Internal venue)
Published: 1st Workshop on MultiModal Learning and Fusion, Amazon Machine Learning Conference, 2021
Abstract:
A collection of 40 binary classification datasets was acquired from an integrated AutoML, active learning, and human labeling system for Amazon products known as ”CPP AutoML”. Each dataset consists of an identical schema of 39 attributes including numeric, categorical, text, image and date attributes. Each dataset represents a real business problem that is being solved by the CPP AutoML platform. In this paper, we discuss the construction and structure of this corpus. We also discuss the challenges of evaluating AutoML algorithms for the “hands off the wheel” business requirements of CPP AutoML. Finally, we present short descriptions and benchmark metrics over this corpus for a collection of algorithms. These algorithms include the CPP AutoML production baseline, two common machine learning baselines, two publicly available Amazon AutoML solutions (AutoGluon and SageMaker AutoPilot), and two novel AutoML solutions. The novel AutoML solutions exhibit particularly strong performance relative to the production baseline. One of these solutions exercises new functionality added to AutoGluon to stack and ensemble a ResNet image model fine tuned on raw image features, used in addition to the tabular models already trained in standard AutoGluon. The other solution, EPS-Ensemble, combines standard gradient-boosted trees and logistic regression models with Transformer networks pre-trained on the Amazon catalog using different self-supervised objectives.
Citation: Andrew Borthwick, Abhishek Divekar, Nick Erickson, Fayaz Ahmed Farooque, Oleg Kim, Nikhil Rasiwasia, and Ethan Xu. "The CPP Multimodal AutoML Corpus and Benchmark". 1st AMLC Workshop on MultiModal Learning and Fusion at the 9th conference of Amazon Machine Learning (AMLC 2021) (Internal venue)
Published: Amazon Machine Learning Conference (AMLC), 2021
Abstract:
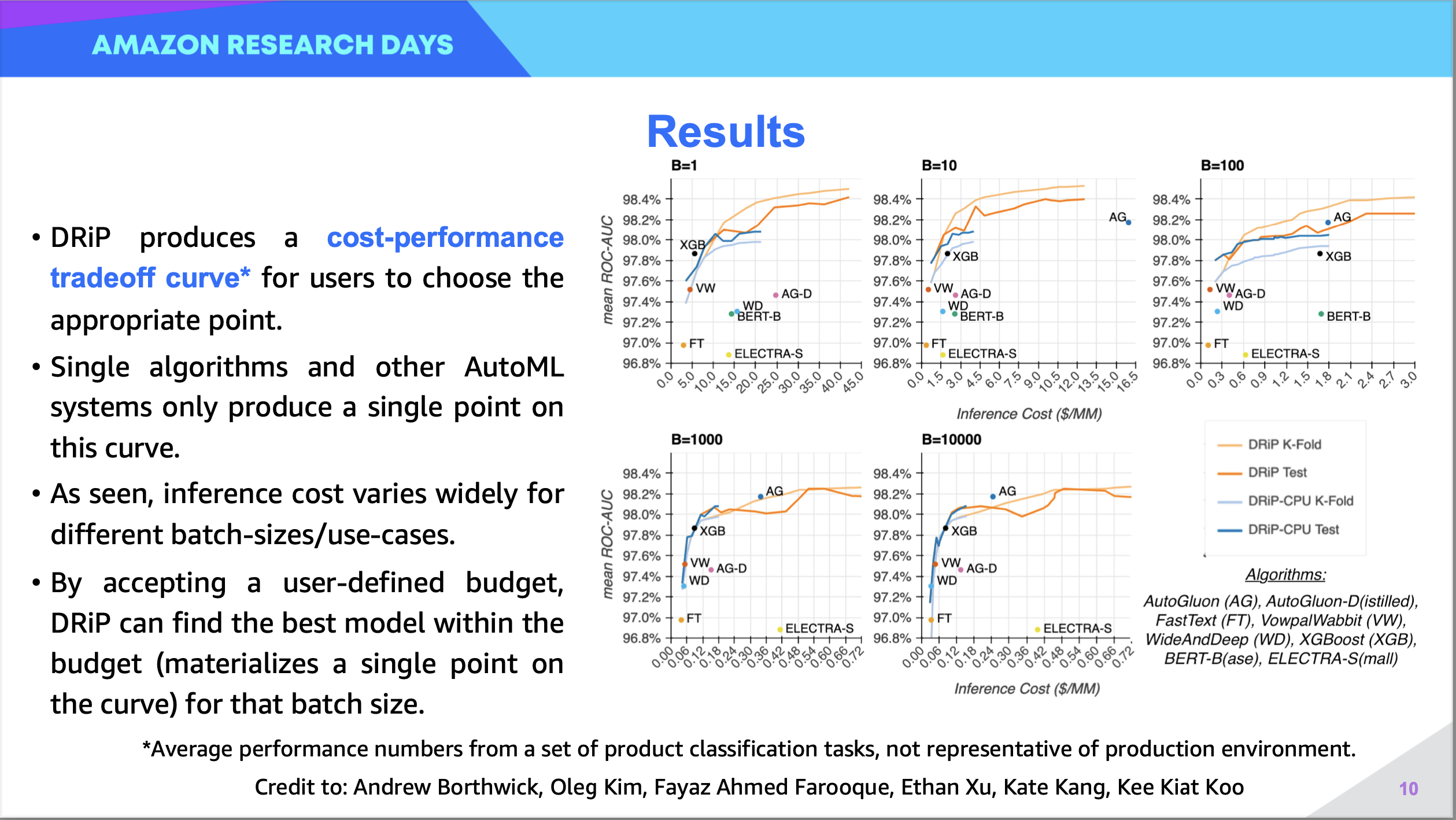
Recent progress in automated machine learning (AutoML), has shown that both hyperparameter search and stacking models can achieve performance that beats the median Kaggle competitor on standard classification metrics [13]. However, solutions that directly optimize cost of executing such models within minimal loss of performance have been sparingly explored. The challenge faced by current techniques is the lack of apriori knowledge of the deployment environment in which the model must operate, and its associated constraints (such as request batch-size or prediction latency). This shortcoming, however, affects a critical subset of users: business teams having cost-sensitive use-cases, who are unable to meet their goals if an AutoML-suggested model is expensive during training or inference. To bridge this gap, we propose DRiP, a versatile ML framework which encapsulates the phases needed for an automated system to select and iteratively refine candidate models while being constrained by an inference budget. We find that existing tools have individual capabilities that map to phases in our framework, but lack the overall capability to optimize against such constraints. Thus, we present our implementation of this framework as a new AutoML tool. When compared across 38 product classification datasets and various business use-cases, we find that DRiP is able to obtain 99.96% of the ROC-AUC performance of the best SOTA AutoML systems (AutoGluon and H2O.ai) at 37% of the cost. When tuned to minimize cost, DRiP offers better cost and performance than comparably optimized AutoML systems (average 0.21 ROC-AUC increase at 44% of the cost of distilled AutoGluon). If no cost constraints are imposed, “Unrestricted” DRiP provides the best overall performance (98.42 ROC-AUC vs 98.18 for next-best AutoML system). Although we evaluate classification, the framework can be used to automatically optimize any machine learning task having well-defined performance and cost.
Citation: Abhishek Divekar*, Gaurav Manchanda*, Prit Raj, Abhishek Das, Karan Tanwar, Akshay Jagatap, Vinayak Puranik, Jagannathan Srinivasan, Ramakrishna Nalam, and Nikhil Rasiwasia. "Squeezing the last DRiP: AutoML for cost-constrained product classification". 9th conference of Amazon Machine Learning (AMLC 2021) (Internal venue)
Published: (Preprint), 2023
Abstract:
Unsupervised text augmentation has gained attention in recent years, as approaches which use pre-trained models to produce high-quality augmentations (such as Backtranslation [48]) are replacing simple rule-based noising to attain SOTA performance in fully- and semi-supervised settings [53]. Such approaches have benefits over other model-based text augmentations, as they are applicable to most natural language tasks and their efficacy does not rely on the availability or quality of ground-truths. However, it is difficult to ensure augmented covariates are neither homogeneous nor invalid. To address this, we introduce GROK Score, an unsupervised metric which measures the paraphrase quality of generated text: fluency, semantic fidelity and diversity. When used to re-rank and filter outputs from Beam Search decoding on pre-trained generative models, GROK captures a small subset of diverse generations, which are used as augmentations. We evaluate this strategy in realistic scenarios: “challenging” Amazon Product classification problems from the CPP MultiModal corpus (2.75-3.87 ROC-AUC below the average) with limited text data. Our results indicate that GROK requires 69.5% fewer augmented samples to match the performance of Backtranslation and rule-based Easy Data Augmentation (EDA) [51] across six classification algorithms. Additionally, tuning the GROK-filtering threshold using K-Fold cross-validation leads to an average lift of 0.28 ROC-AUC, improving performance over both EDA and Backtranslation for all algorithms, while requiring 30% fewer augmented samples (achieving 0.53 ROC-AUC lift for VowpalWabbit and 1.10 for WideAndDeep). Human evaluations comparing GROK to prominent metrics like BLEU, METEOR and ROUGE validate our hypothesis that GROK promotes text generations having high diversity, indicating its utility beyond augmentation.
Citation: (Preprint) Abhishek Divekar, Mudit Agarwal, Srujana Merugu, and Nikhil Rasiwasia. "Unsupervised text augmentation using Pre-trained Paraphrase Generation".
Published:
Abstract:
Current AutoML research aims to minimize the Discovery time of high-performing models, e.g. "find best model within 30 mins". However, ideally most models are trained, and used in production for months before refresh, meaning the costs operational cost of running an AutoML model in production far exceeds the one-time discovery cost. Instead, can AutoML systems discover high-performing models which operate within an explicit budget? We propose a new AutoML paradigm, DRiP (Discover-Refine-Productionize) which not only allows cost-backwards optimization, but produces a cost-performance tradeoff curve for users to choose an appropriate point. We compare to AutoGluon v0.2 and find that DRiP AutoML can be tuned to achieve: (i) On-par performance at low cost (ii) Minimum overall cost (iii) Maximum overall performance.
Citation:
Published:
Abstract:
Amazon ML Summer School 2022 was an initiative which enrolled ~3,000 Indian undergraduate students and helped them learn key ML technologies from Amazon Scientists. I taught a module on Supervised Learning covering Decision Trees, Bagging and Boosting algorithms, followed by a 3-hour Q&A session to clarify student questions.
Citation:
Published:
Abstract:
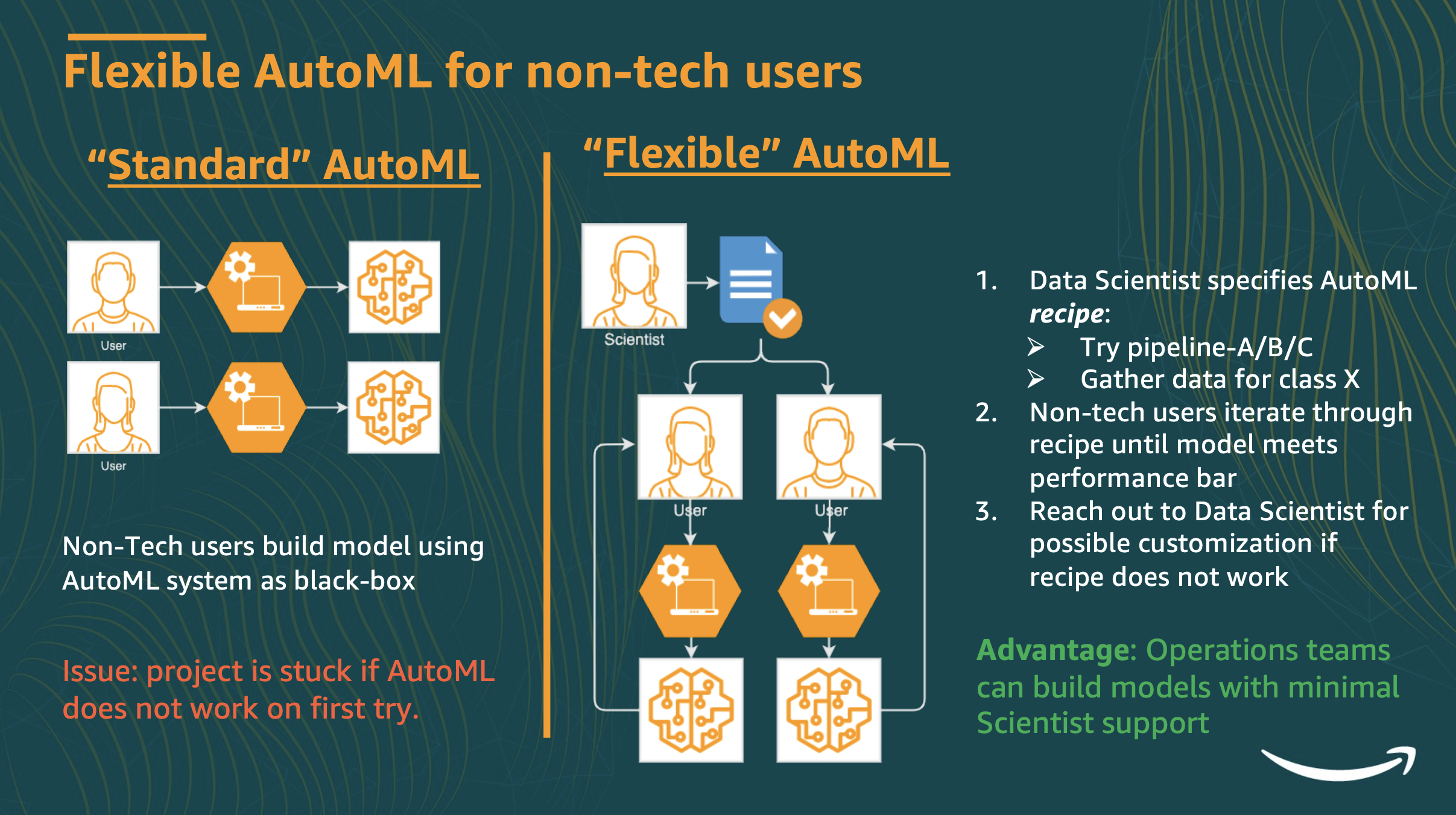
Current AutoML systems consider only two scenarios: (i) AutoML model meets performance bar, or (ii) model misses performance bar. Efforts have been dedicated to improving this ratio, but common issues are not addressed: (iii) model missed performance bar by 1% (iv) model is too slow in production (v) Custom model needs 6+ months to deploy. Different AutoML user-personas (Data Scientists, Engineers, Non-Tech) face different issues depending on their background. Flexible AutoML is a paradigm which addresses the needs of all personas. We present an experimentation platform, Litmus, which provides convenient interfaces for experimentation for each user-persona, is exetensible to new ML paradigms, and scales to large models and datasets. We further discuss how Litmus accelerates AutoML adoption across Amazon.
Citation: