Extending Whisper, OpenAI’s Speech-to-Text Model
Team: Abhishek Divekar, Yosub Jung, Roshni Tayal
Resources: [Technical report]
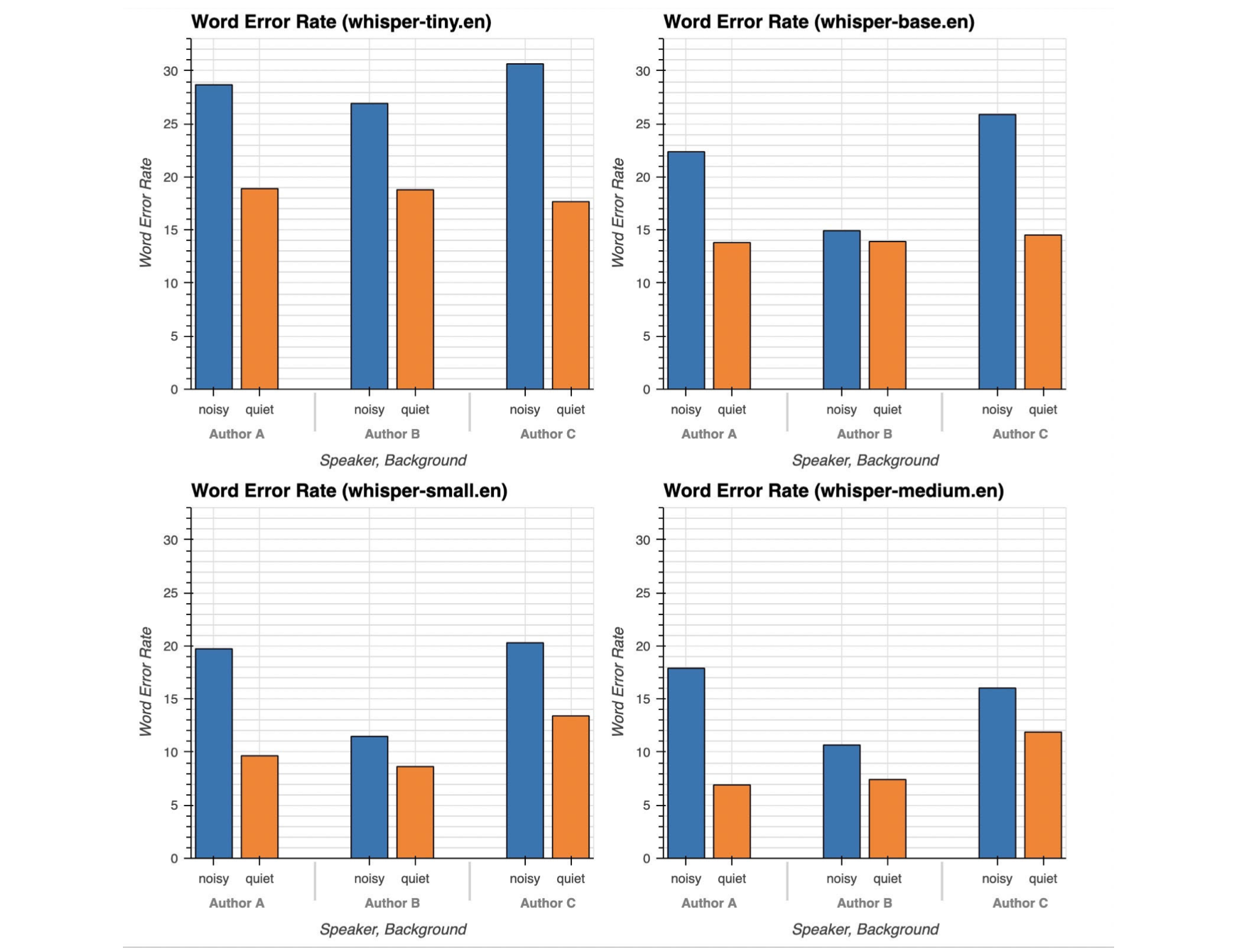
Summary: We study the performance of OpenAI's Whisper model, the state-of-the-art Speech-to-text model, in noisy urban environments. To do so, we create a dataset consisting of 134 minutes of us reading out loud in both quiet and noisy urban environments (subway, street and cafe) and manually annotating the recordings at 30 second intervals. Using a powerful multi-GPU AWS cluster and distributed computing framework Ray, we find that Whisper performs significantly worse on speeches recorded in noisy environments than on those recorded in quiet environments, in contrast to assertions made by Whisper authors. This performance gap is particularly severe for small Whisper models. This finding is concerning since the small models, due to its low inference-time, are most likely to be deployed on handheld devices (like smartphones), and thus more likely to be exposed to outside noise that can degrade speech-to-text performance. To improve performance, we fine-tune the HuggingFace Whisper implementation on a split of our collected data. We find that fine-tuning on single-speaker noisy speech improves average Word Error Rate (WER) by 2.81 (from 28.76 to 25.95) and fine-tuning on multi-speaker noisy speech improves average WER by 2.61 (from 28.76 to 26.15). Thus we are able to successfully adapt OpenAI Whisper to function reliably in noisy urban environments.
My contribution: Helped formulate research question, recorded and annotated speeches, coded and fine-tuned hundreds of HuggingFace Whisper models uinsg Ray distributed computing framework, tabulated results, minor rewriting.