Flexible AutoML: Accelerating AutoML adoption across Amazon
Talk at 2nd International Conference on AI-ML Systems (AIMLSys 2022), Virtual
Resources: [Slides]
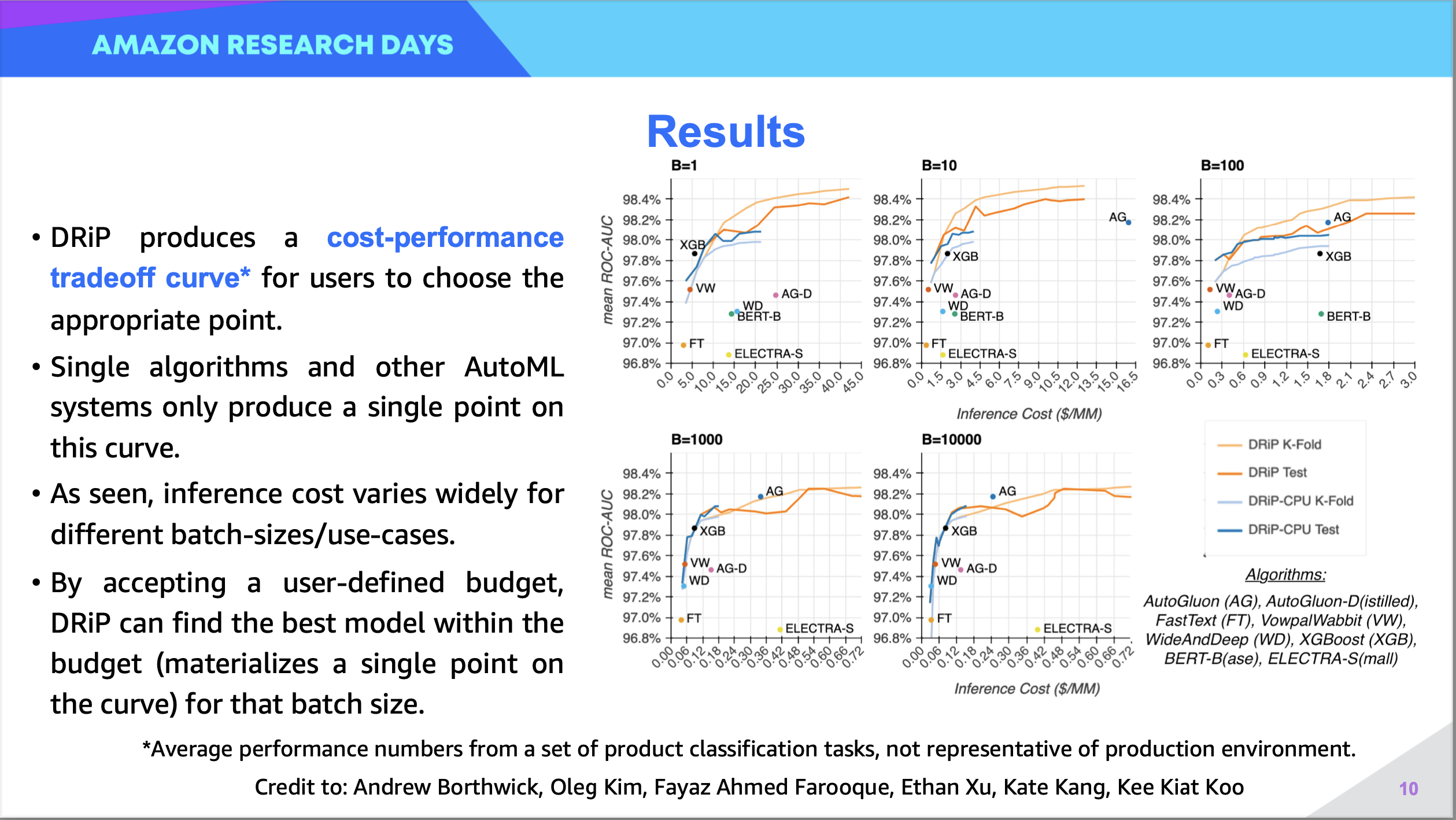
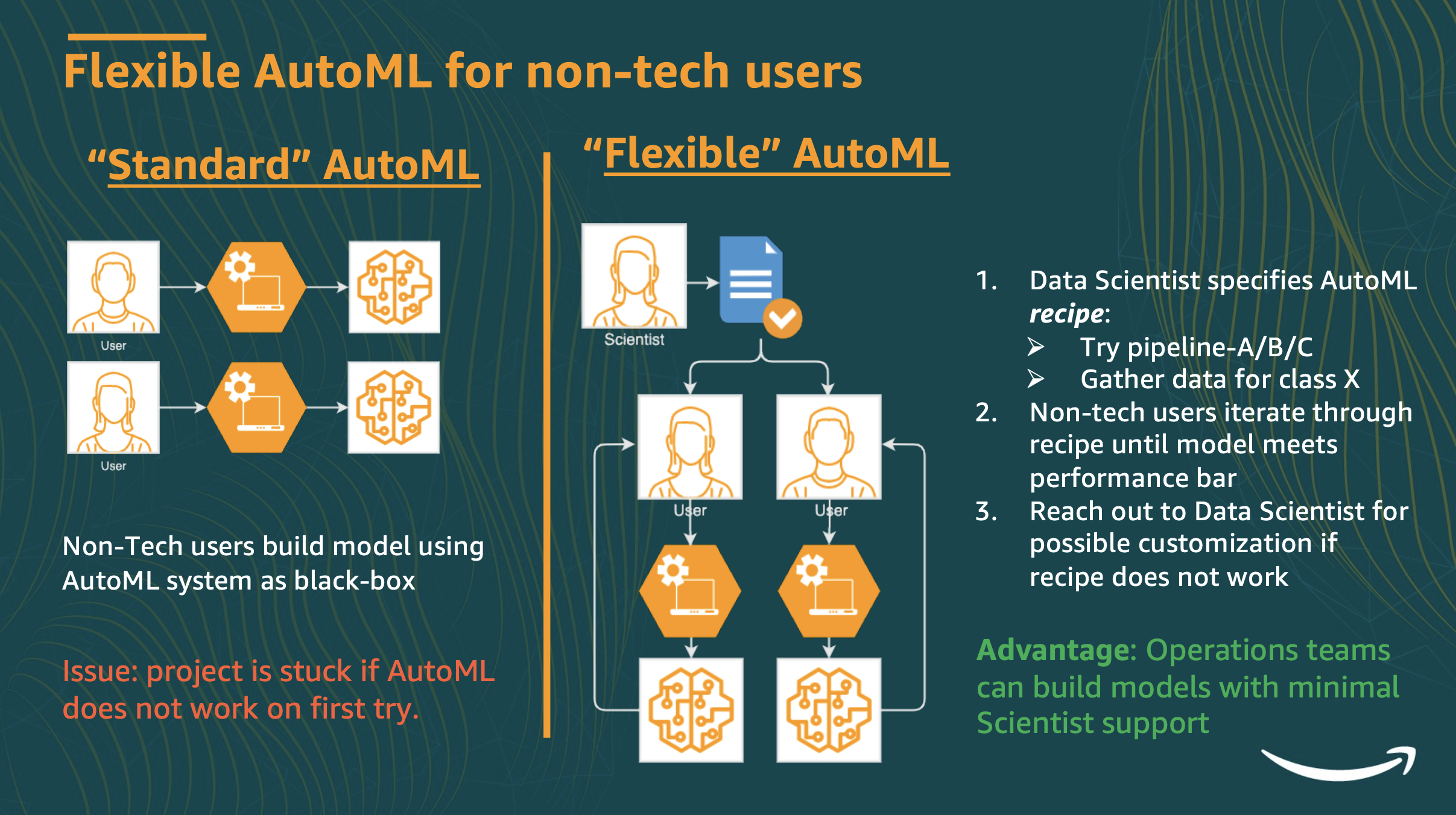
Abstract: Current AutoML systems consider only two scenarios: (i) AutoML model meets performance bar, or (ii) model misses performance bar. Efforts have been dedicated to improving this ratio, but common issues are not addressed: (iii) model missed performance bar by 1% (iv) model is too slow in production (v) Custom model needs 6+ months to deploy. Different AutoML user-personas (Data Scientists, Engineers, Non-Tech) face different issues depending on their background. Flexible AutoML is a paradigm which addresses the needs of all personas. We present an experimentation platform, Litmus, which provides convenient interfaces for experimentation for each user-persona, is exetensible to new ML paradigms, and scales to large models and datasets. We further discuss how Litmus accelerates AutoML adoption across Amazon.